// case study · tooling
Five agents that read the paper so you don't have to.
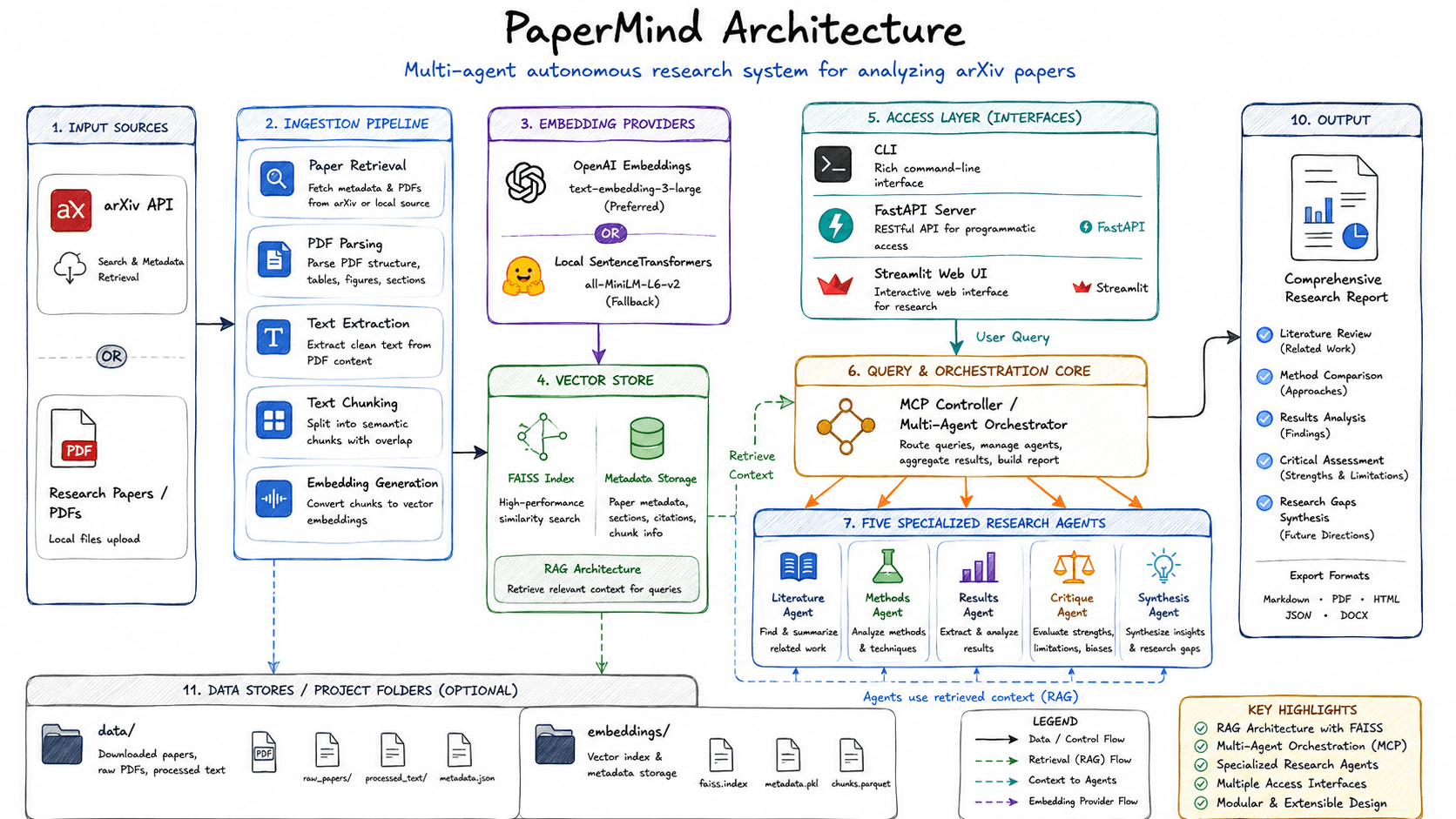
An autonomous arXiv research assistant that fetches papers, builds a FAISS index, and orchestrates five specialist agents to produce a literature review, methods comparison, results analysis, critique, and gap synthesis in one report.
- Period
- Jan 2026 – May 2026
- Role
- Sole engineer
- Repo
- GitHub
Keeping up with a moving field means reading the same kinds of questions out of every new paper: what's the contribution, how does it compare to prior work, what are the results, where does it fall short, and what's the open question? PaperMind automates that loop. You point it at an arXiv ID (or drop in a PDF), and it produces a single research report by routing the work across five specialist agents, each with its own retrieval window and prompt shape.
The pipeline
- Ingestion. arXiv API or local PDFs →
PyPDFstructural parse → clean text extraction → semantic chunking with overlap. - Embedding. OpenAI
text-embedding-3-largeby default, with a localall-MiniLM-L6-v2SentenceTransformeras a fallback so the system keeps working offline. - Vector store. FAISS index for similarity search, paired with a metadata store for paper sections, citations, and chunk lineage.
- Orchestration. An MCP-style controller routes a user query to the agents and aggregates their outputs into a unified report.
- Access. CLI for scripts, FastAPI for programmatic integrations, Streamlit for the interactive web view.
The five agents
- Literature Agent: finds and summarises related work the paper cites or competes with.
- Methods Agent: extracts the technique, ablation structure, and where it differs from prior approaches.
- Results Agent: pulls numbers, benchmark tables, and headline claims out of the experiments section.
- Critique Agent: evaluates strengths, limitations, and likely failure modes that aren't explicit in the paper.
- Synthesis Agent: turns the four upstream outputs into a coherent narrative with a research-gap section and suggested next questions.
Why split it into agents
One big prompt that tries to do all five jobs at once gives mediocre everything. Splitting them lets each agent retrieve a different slice of the paper, use a different prompt shape, and be evaluated independently. The Critique Agent in particular needs a wider retrieval window (it has to look at both the paper and its neighbours) than the Methods Agent (which usually only needs the method section).
Output
Reports export to Markdown, PDF, HTML, JSON, or DOCX. The JSON export is structured so a downstream pipeline can pick up specific fields, e.g. for a literature-review aggregator or a paper-of-the- week digest.
What I'd do next
- Add a citation-graph retrieval step so the Literature Agent can walk the cite tree rather than only operating on chunks of the current paper.
- Run an eval set comparing PaperMind reports to human-written summaries on a few well-known papers, using a small benchmark and grading each agent independently.
- Streamline the Streamlit UI into a single view per paper instead of the current tabbed layout.