// case study · production
Routing three foundation models at 1.5s p95 without paying for it twice.
A production multi-model LLM inference layer behind enterprise applications, owning latency, cost, and reliability under varying load.
- Period
- Feb 2024 – Jul 2024
- Role
- Generative AI Engineer at Concentrix + Webhelp
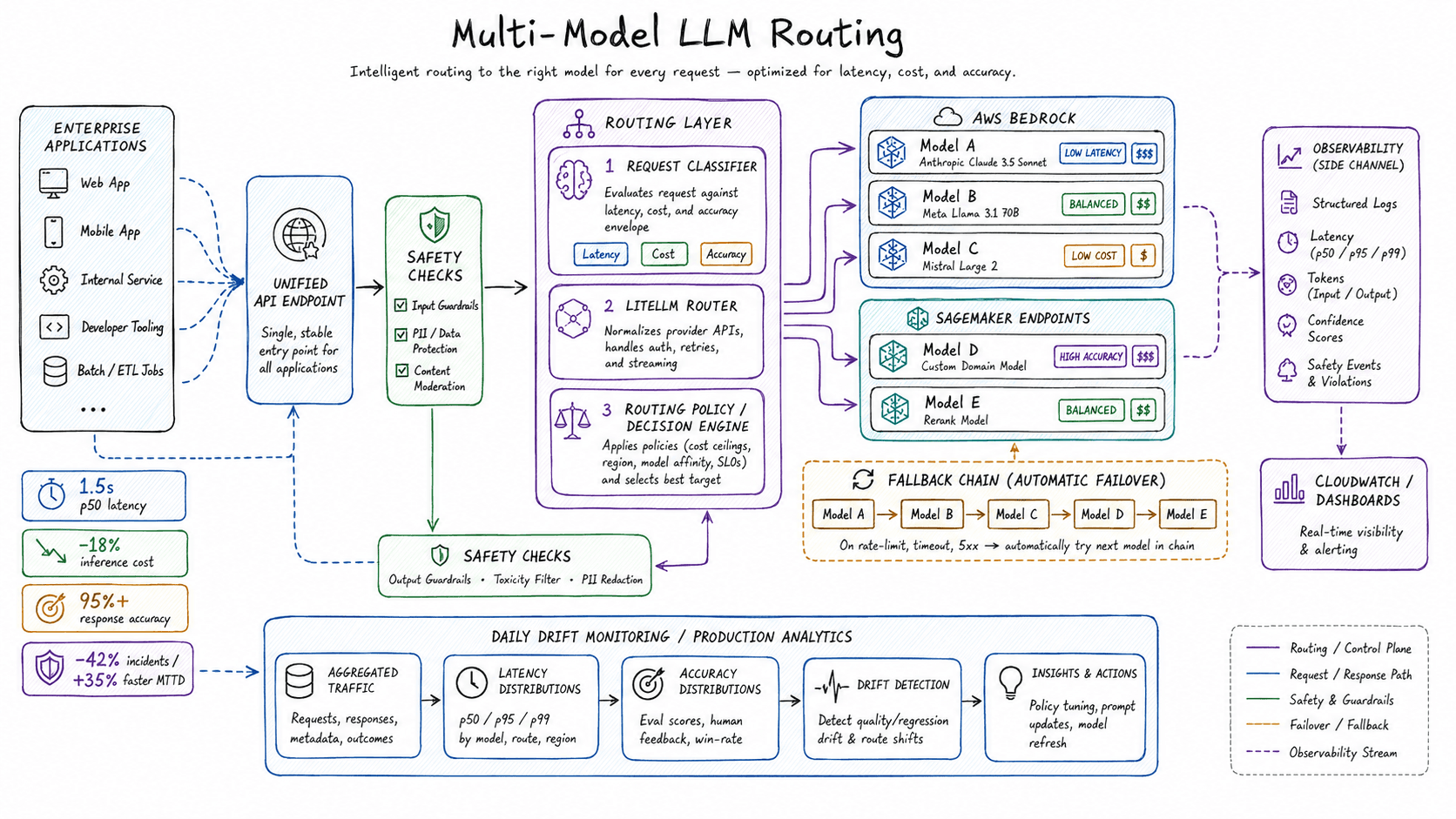
Enterprise teams wanted access to multiple foundation models from one stable endpoint. Each model had a different cost curve, a different latency profile, and a different failure mode. The naive fix (pick one model and stick with it) left money on the table and made every outage a full outage. The better fix was to put a routing layer in front of all of them and treat model choice as a tunable knob.
The constraints
- Latency budget. Production p95 latency had to improve from a 4s baseline while preserving response quality.
- Cost ceiling. Inference spend was the largest line item in the platform's monthly bill.
- Accuracy floor. Routing decisions could not silently degrade response quality.
- Operability. When a model misbehaved, on-call needed to know in minutes, not days.
The architecture
- Router. LiteLLM in front of AWS Bedrock and SageMaker endpoints, plus a request classifier that decided which model could meet the request's latency-cost-accuracy envelope.
- Fallback chain. Every route had a sibling model it could fall back to on rate-limit or 5xx, so a single provider blip never became a user-visible outage.
- Observability. Structured logging into CloudWatch with per-request model, latency, token, and confidence; safety checks ran inline and emitted their own stream.
- Drift monitoring. Daily aggregates over production traffic that flagged accuracy and latency distributions creeping outside their bounds.
1.5s
Production p95 latency
down from 4s
$45K to $37K
Monthly inference spend
routing, caching, and fallback
95%+
Task success
under varying constraints
−42% / −35%
Incidents / MTTD
thanks to inline observability
What worked
- Routing on a budget, not a vibe. The classifier picked the cheapest model that could meet the request's latency-accuracy envelope, not the “best” model globally. That's where most of the cost win came from.
- Cheap observability beats expensive intuition.Structured per-request logs and a couple of dashboards bought most of the incident reduction. The router itself was simple; the visibility around it was the moat.
- Fallbacks earned their keep on day one. Within the first week, a single Bedrock endpoint started returning inflated latency on a fraction of requests. The fallback chain absorbed it before anyone noticed.
What I'd do differently
- Move classification logic from heuristic to a small fine-tuned classifier earlier. The heuristic was good enough to ship but ate engineering time as the model menu grew.
- Pre-compute a per-tenant routing policy rather than a single global one. Variance between enterprise customers' mix of requests turned out to be larger than I expected.